近日,中心在National Science Open期刊在线发表文章“Strategies for training optical neural networks”。文章首次系统性地总结了目前主流光学神经网络的训练策略,并对不同策略的优劣势进行分析,最后对目前光学神经网络在训练方面所遇到的瓶颈问题及未来发展方向进行了总结与展望。

图1. 论文截图
深度学习技术近年来在计算机视觉、自然语言处理等领域产生着重要作用。随着后摩尔时代的到来,传统微电子处理器已经难以满足深度学习任务对于高算力和低能耗的巨大需求。得益于光子大带宽和超高速的优势,利用其实现深度学习任务能够实现计算能效和速度的巨大提升。因此,基于特定光学结构所实现的神经网络加速器被广泛视为下一代深度学习专用计算硬件。
目前,光学神经网络已经实现了元音识别和手写数字识别等任务。然而,在面对更加复杂的计算任务时,如端到端的目标检测,光子神经网络却难以完成。一个原因是目前主流光学架构难以实现超大规模的神经元部署,限制了神经网络的表达能力。这个问题可以通过未来新型的架构设计和光学神经元复用来解决。而另外一个更加主要的原因是,光学神经网络缺乏大规模且高效快速的训练策略。不同于反向传播在传统训练策略中的普适性,光学神经网络因光学实现结构不同,其训练策略也有所差异。目前主流的训练策略有三类,第一类in-silico的策略依赖于将预训练好的权重数据通过查值表的方式映射到光学神经网络,但是这种方式鲁棒性不强,容易受到环境变化影响而失效。为了提升训练的鲁棒性,第二类策略采用in-situ的训练方式,通过使用基于梯度和无梯度的算法,光学神经网络能够更好的抵抗外界环境变化以及工艺误差所带来的不利影响。然而,该类训练策略缺少对于内部信息的获取机制,在算法收敛速度上面临一定困境。第三类则将in-silico和in-situ的训练策略进行结合,解决了内部梯度信息难以获取的问题。但因其使用了电域的神经网络模型,这种训练策略只能作用于光学神经网络的推理端。为了解决目前训练策略无法大规模部署且效率不高的问题,系统内部信息的快速获取机制与软硬件协同的架构设计需要在未来着重考虑。
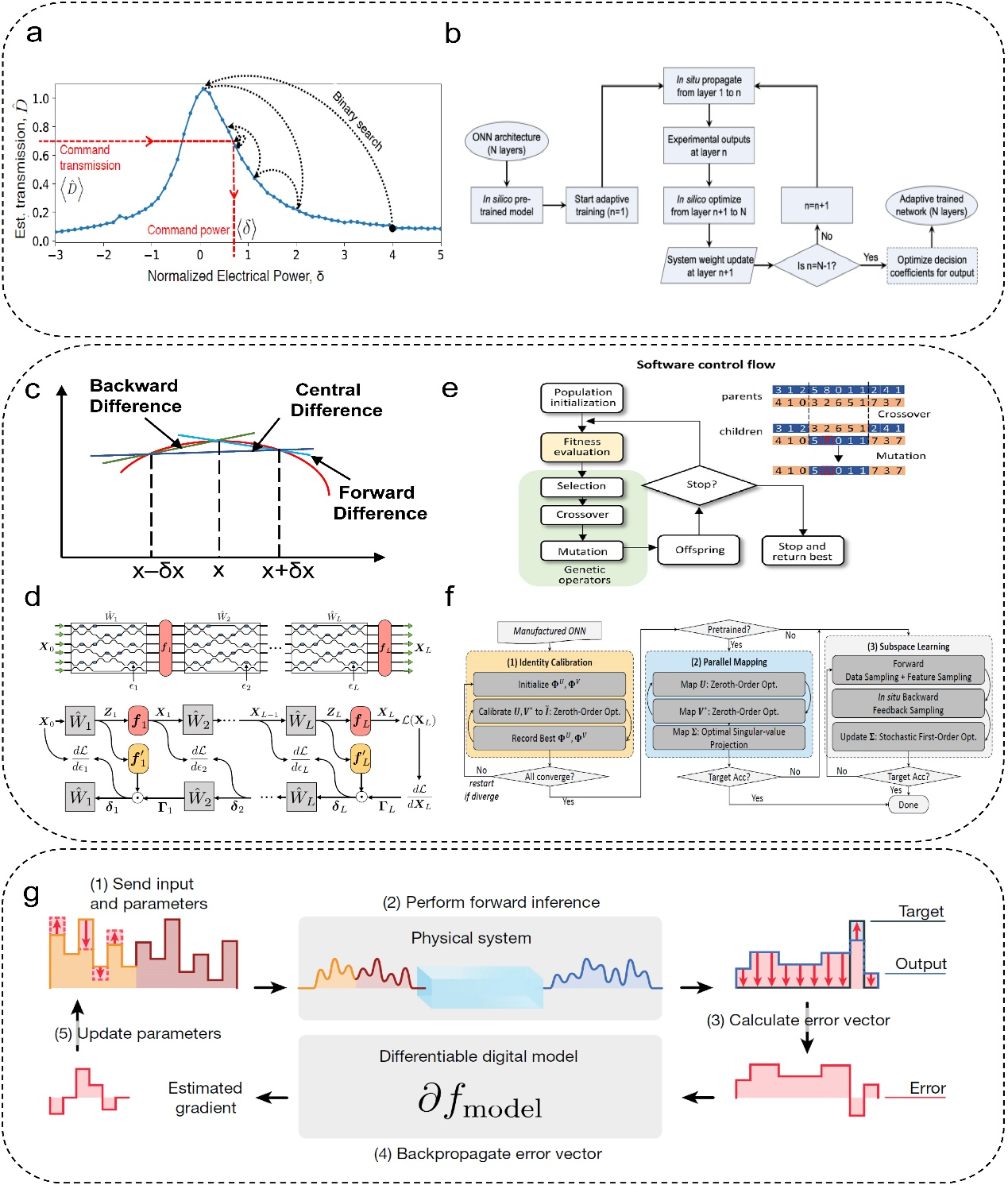
图2. 不同光学神经网络训练策略流程图
该论文的第一作者为2020级博士研究生杨其鹏。通讯作者为电子学院王兴军教授,中心博雅博士后白博文。主要合作者还包括电子学院胡薇薇教授。该工作由北京大学电子学院区域光纤通信网与新型光通信系统国家重点实验室作为第一单位完成。
论文原文链接:
https://www.nso-journal.org/articles/nso/full_html/2022/03/NSO-2022-0042/NSO-2022-0042.html
